背景
最近,由于某些原因,特别关注了医疗知识图谱方面的发展&应用情况,有了些浅薄认识,故码此文,以供参考。
随着智能时代的到来,把临床数据、临床指南、组学数据通过大数据、知识图谱、可视化系统结合,核心医学概念的全面覆盖、医疗生态圈内全方位知识数据的聚合,构建综合医疗大脑,给临床医生、科研工作者、管理工作者提供帮助,成为未来医疗的发展方向。
Tips: 临床数据:医院信息系统的电子病历、影像、检验等一大堆专业临床业务系统产生的数据集合。 临床指南:针对特定的临床情况,帮助临床医生和患者根据特定的临床情况做出恰当决策的指导意见。 组学数据:如基因组学、蛋白组学及代谢组学产生的生物信息数据,医院另一个数据中心。
想法
既然是综合的医疗大脑,那么满足多样化的应用场景是必要条件,提供语义搜索、知识问答、临床辅助、疾病趋势预测、疾病易感人群、热词搜索标签云、预防、疾病所需检查、忌吃食物、理疗食谱等等。从大量的医疗新闻、临床指南,医院历史数据,药品库、疾病库、处方库、风险因子库和医疗资源库,建立起实体之间的语义关系,最后形成知识图谱、医学大脑、成为社会化医疗应用。
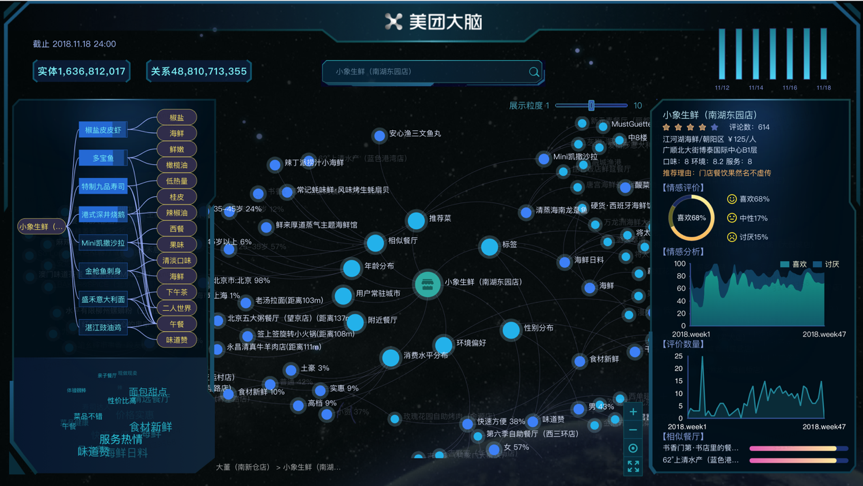
以美团餐饮大脑为参考,构建综合性医学大脑,邀请更多医疗机构参与合作,共同构建完整的医学大脑,包括疾病症状、用药参考、以及从海量病例中挖掘的经验知识等等,以疾病、症状、用药、问诊等节点,建立精准的关系结构,实现智能化的诊疗知识图谱。如果单纯按照临床数据、临床指南、组学数据等数据图谱化没有太大的发展意义。 如CMeKG中文医学知识图谱,属学术研究不做过多评价。
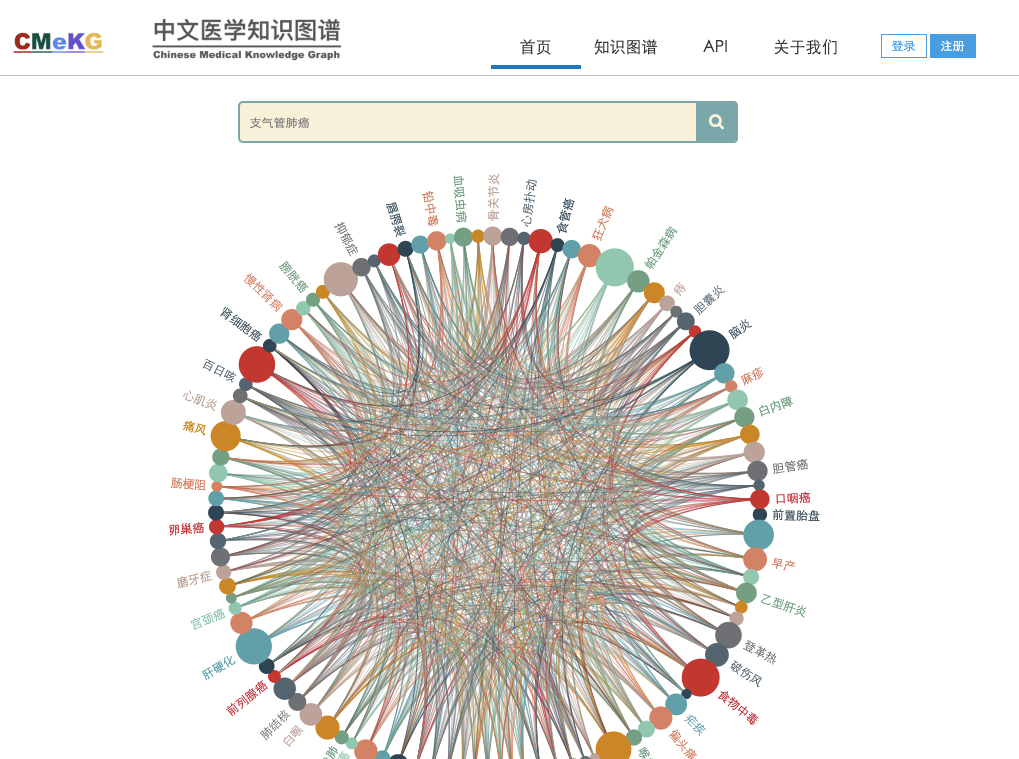

CMeKG目前是1.0版,包括:6310种疾病、19853种药物(西药、中成药、中草药)、1237种诊疗技术及设备的结构化知识描述,涵盖疾病的临床症状、发病部位、 药物治疗、手术治疗、鉴别诊断、影像学检查、高危因素、传播途径、多发群体、就诊科室等以及药物的成分、适应症、用法用量、有效期、禁忌证等30余种常见关系类型, 关联到的医学实体达20余万,CMeKG目前的概念关系实例及属性三元组达100余万。CMeKG仅供学术研究使用,不做商业用途。
行业难点
医疗、金融等细分领域的智能化过程中,行业本身面临着诸多困境,医惠科技何国平讲到了医疗行业的四座大山:
- 1、医疗信息化的发展有20多年的历史,期间出现多条发展路线,使得采集数据不连续或维度单一,数据价值大打折扣;
- 2、数据分散在很多业务系统,数据掌握业务商手中,不同业务商的数据标准结构不同,造成数据的清洗、整理非常困难;
- 3、不同医院、不同医生对病情的描述方式存在差异,计算机无法理解这些表达,需要对采集到的数据进行标准化处理,标准化的过程非常困难;
- 4、对数据进行充分挖掘、转化为知识,尤其在数据体量非常庞大的情况下,也存在很大的困难。
针对以上问题,我在调研过程中发现OMAHA七巧板医学术语集文档,只不过加入使用需要支付昂贵的费用,这里我列出一些官方提供的文档作为参考:
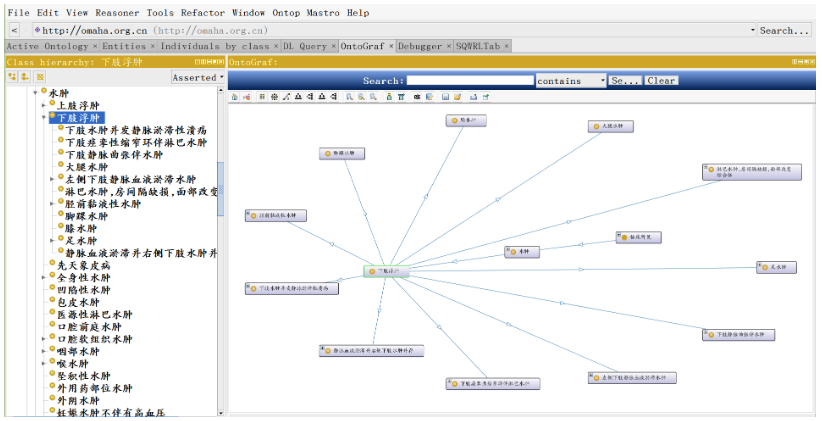
以前由专家收集整理信息的建设方式消耗巨大的资金与时间,至今仍没有一个较为完整的医学知识图谱。中文医学术语建设更是严重落后于发达国家,严重医疗大数据技术的发展。
医疗本身的局限性。如医学临床指南,对疾病临床治疗过程如果严格按照指南来做,哪怕出现了差错,从法律的角度,承担的责任也比较有限;如果没有按照指南来做,产生了差错,那责任就会比较大,所以医学临床指南的加入在智能化的过程中会非常重要。互联网上存在很多半结构化的医学临床指南,比如丁香园、名医百科、中华医学会、医脉通,经常会公布一些指南。
医学数据处理中指代消解、实体消歧的工作量不比一般行业少。期刊论文,病程记录,不同医院,不同医生,表达习惯千差万别,比如发热、发烧、高烧、低烧、39度,医生想要表达的就是发烧,但是计算机理解不了。所以数据的标准化,是数据实体化的关键。
数据的标准化以后,就是数据的实体化。举个例子,如何诊断小儿麻痹症?它的多临床表现有哪些?检验指标是什么?判断一个小儿麻痹症,在诊断出小儿麻痹症以后,根据医学临床指南,他要吃什么药?要做什么检查?做什么康复等等,有一系列指南。把这些描述标准化,建立语义关系,就是数据实体化。
对于广大普通用户,医学知识科普也面临着三大难题:
网络医疗信息鱼龙混杂,难辨真假; 优质的医学内容分散,难检索; 自然语言与医学专业术语之间的差异,搜索不精准。
应用举例
搜狗明医在医疗领域进行了三方面应用:
-
1、权威医学内容的呈现。在搜索某个疾病,会出现该疾病的概述、症状、治疗护理和专家意见等卡片式的内容呈现,方便让用户对疾病有更全面和清晰的了解。
-
2、推理计算。搜索某个症状时,将该症状可能会涉及的疾病以及概率计算出来,同时将科室和具体的症状列出供用户参考。甚至当用户搜索某个疾病后,利用医院的地理位置和科室设置等信息,直接计算出和推荐离用户最近的医院。
-
3、智能分诊系统。智能辅助问诊机器人,通过用户提交的症状对疾病的类型、就诊建议等作出判断和推荐。除了文本和语音技术之外,将图像识别技术应用于智能自诊推出“湿疹痱子识别”功能,当家长上传宝宝患处照片后,帮助家长判断宝宝身上的红斑可能是湿疹还是痱子。
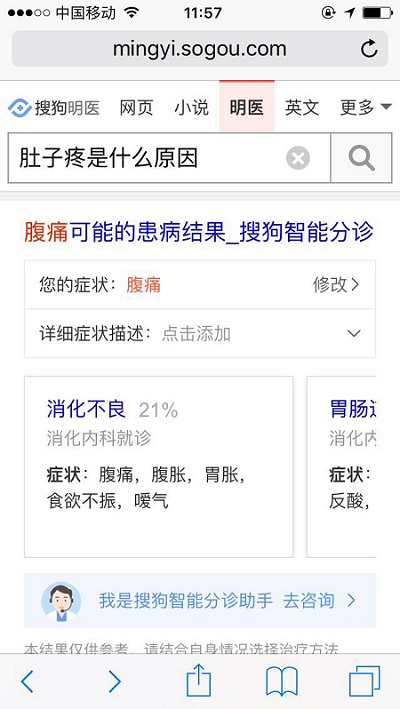
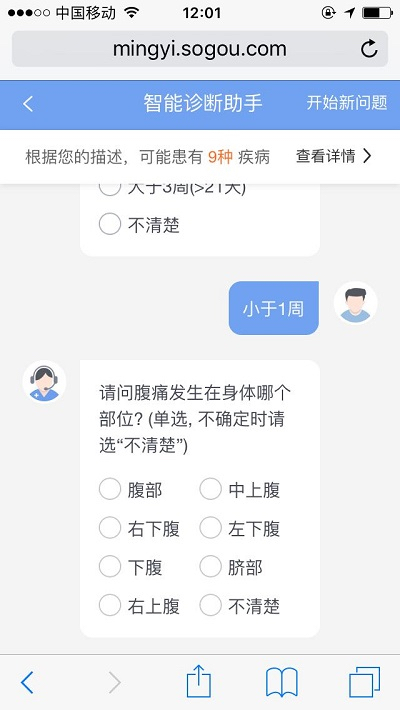
展望
在智能医学的发展当中,必须在可解释性、可循证性、资源可信度上做大量工作。将医学文献知识转变为医疗知识图谱,也包括将海量病例中挖掘的经验知识转变为机器可以理解的表示形式,是医疗知识图谱发展中所必须经历的。同时,图谱数据量大、数据覆盖面广、数据质量高是知识图谱能够走入临床的基础。足够的数据才能帮助辅助诊断做全面的分析,包括:
- 基于疾病与症状关系辅助诊断;
- 基于疾病与检查检验关系推荐检查检验;
- 基于疾病与药品关系及药物相互作用推荐用药;
- 基于指南、文献以及相似病例推荐医疗证据。
持续积累有效的治疗案例和数据,不断累积经验,持续学习,建立持续、快速的成长模式。构建针对不同的医疗管理与临床环节,覆盖诊前、诊中、诊后全流程端到端的解决方案。
根据疾病症状分析系统,通过智能辅助诊断根据病人的描述来预测可能的疾病,给出一些确诊疾病相关的检查,用药环节,系统会在此前医生确诊的基础上,自动给出可用药物、剂量、剂型、频次。医生还可运用机器对病历进行汇总、复盘,找出可能存在诊断问题的病历,减少医生的出错率。建立读片标准和成像参数,构建多模态多病种影像平台,降低误诊、漏诊率。
技术问题
在医疗领域,抽象本体,归纳实体可以从疾病、症状、检查、检验、体征、药品等维度考虑,包括医生、科室、医院都可以囊括近来。关系是指实体间的关系,比如,针对疾病和症状,关系可有“包含关系”,“不包含关系”,甚至“金标准关系”。疾病和医生可以定义“医生擅长治疗疾病”,医生和医院可以定义“归属于关系”等。
这些可以归纳到Schame构建层面,康夫子张超在介绍知识图谱建设中信息抽取时介绍到:
知识规律发现其实就是pattern learning。人们是按照一定书写方式来描述知识的,数据量越大越能体现出书写的语法及结构。康夫子的一个核心技术即针对要抽取的知识从海量文本中学习这种知识的描述方式。康夫子的着眼点依次是:
1、快,因为医疗知识图谱有上千种关系,处理速度要快; 2、准确率高; 3、覆盖率高,比如要有足够多的疾病与症状的知识,才能分辨出疾病; 4、可控; 5、通用性强。
在这样的标准下,比较推荐简单粗暴可控的框架,即基于模板的抽取。这类方法简洁可控,容易冷启动,准确率可控,通用性也不错。不足是:模板产生困难、覆盖率不高,而且容易产生语义漂移,需要做边界控制,最后是计算复杂度高。这是目前这种计算框架的优劣。
重要图片

医疗知识图谱的难点还在于AI 的基础能力,如自然语言处理、计算速度,模型适配。

可见康夫子的医疗知识图谱技术发展不是完全说大话,还是有一定金刚钻的。
建议想要做知识图谱的公司可以尽早准备入坑,可以在产品设计与技术方面多做积累,不断探索前行。
医学知识图谱构建技术方案介绍可参考该论文《医学知识图谱构建技术与研究进展》:
论文获取方式:公众号对话框回复【KG论文20190529】
