序言
自然语言处理(ML)、机器学习(NLP)、信息检索(IR)等AI领域,评估(evaluation)是一项非常重要的工作,其模型或算法的评价指标往往有如下几点:准确率(Accuracy),精确率(Precision),召回率(Recall)和综合评价指标(F1-Measure)。
简单整理,以供参考。
准确率(Accuracy)
准确率(Accuracy)是一个用于评估分类模型的指标。说人话,模型预测正确数量所占总量的比例。
准确率的伪公式:
1 | |
在二元分类中,可根据正类别与负类别按如下方式计算:
注:下方公式中,TP = 真正例 , TN = 真负例 , FP = 假正例 , FN = 假负例。
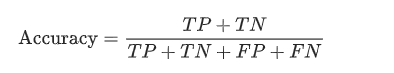
名词释义:
- 真正例(TP): 正例样本被标记为正例。
- 假正例(FP): 假例样本被标记为正例。
- 真反例(TN): 假例样本被标记为假例。
- 假反例(FN): 正例样本被标记为假例。
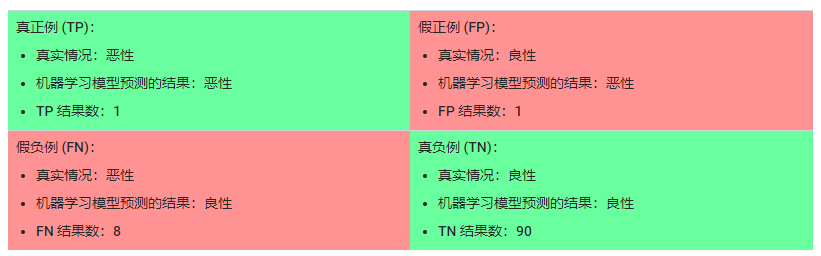
试举例计算模型的准确率,假设某模型将100个肿瘤分为恶性(正类别)或良性(负类别):
根据上述例子的数据我们来计算该模型的准确率:
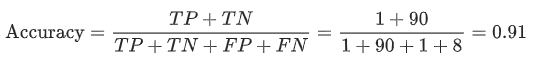
乍一看,该模型的准去确率为0.91,也就是91%,(100个样本中有91个预测正确),这是不是可以表示我们的肿瘤分类器在识别恶性肿瘤方面酒标的非常出色呢?
带着这个疑问,我们仔细分析一下正类别和负类别,深入理解该模型的效果。
100个肿瘤样本中,91个为良性,其中,1个FP(假正例)& 90个TN(真负例),9个为恶性,其中,1个TP(真正例)&8个FN(假负例)。
整个样本中有91个良性肿瘤,该模型将90个样本正确识别为良性肿瘤,将1个样本识别为恶性,这个效果很好。但是,在9个恶性肿瘤样本中,将8个样本识别为良性,9个恶性肿瘤有8个未被诊断出来,8/9,这个结果多么可怕!!!
91%的准确率,看起来还不错,如果另一个肿瘤分类器模型总是预测良性,那么这个模型使用我们的样本进行预测,也会得出相同的准确率。
换句话说,该模型与那些没有预测恶性肿瘤和良性肿瘤的模型差不多。
还有,当我们使用分类不平衡的数据集(如:正类别标签与负类别标签数量存在明显差异)时,就一项准确率并不能反映情况。
为了更好的评估分类不平衡的数据集问题,下面引入精确率(Precision)和召回率(Recall)
精确率(Precision)
精确率为解决在被识别为正类别的样本中,为正类别的比例。精确率的公式定义如下:
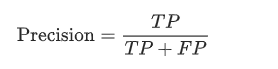
Tips: 如果模型预测结果中没有假正例,则模型的精确率为1。
那我们来接着上面肿瘤预测的样本结果来计算其精确率,好,接着看预测样本分布图:

其精确率的计算结果为:
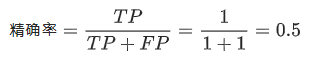
可以看到该肿瘤预测模型的精确率为0.5,换句话说就是,该模型在预测恶性肿瘤方面的正确率是50%。
召回率(Recall)
召回率为解决在所有正类别样本中,被正确识别为正类别的比例。召回率的公式定义如下:
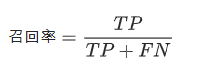
Tips: 如果模型的预测结果没有假负例,则模型的召回率为1.0。
同样使用上述肿瘤预测的样本结果来计算其精确率,看预测样本分布图:

召回率的计算结果如下:
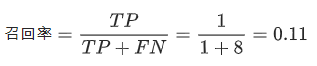
由以上结果可以看出,该模型的召回率为0.11,那么,就可以说,该模型的能够正确识别出所有恶性肿瘤的百分比是11%。
想要全面评估模型的有效性,必须同时检查精确率与召回率。但是,很遗憾,精确率和召回率往往是此消彼长。也就是说,提高精确率通常会降低召回率,反之亦然。
好,带着这个问题,我们来看一个综合评价指标(F1-Measure)
综合评价指标(F1-Measure)
F-Measure是一种统计量,又称F-Score,也是精确率(Presicion)和召回率(Recall)的加权调和平均,常用于评价分类模型的好坏。 -来自百度百科
F-Measure数学公式为:
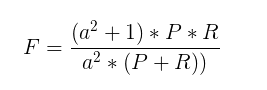
如上式中,P为Precision, R为Recall,a为权重因子。
当a = 1时,F值变为最常见的F1了,代表精确率和召回率的权重一样,是最常见的一种评价指标,因此,F1的数学公式为:
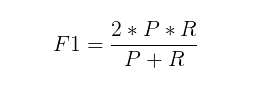
根据前面的出的精确率和召回率,便可得出其F1值:
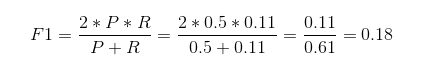
F1 综合了精确率和召回率的结果,当F1较高时,则说明模型或算法的效果比较理想。
ChangeLog
- Create on 2019-04-11
