前言
如前文所述,浏览器应用有两种不同的视图,即文档视图与摘要视图,视图的形式取决于所选对象的基本类型。
-
若对象的基本类型是文档(Document),则用户将看到一个文档选项卡,该选项卡显示文档的原始文本;
-
若对象基本类型是实体(Entity)或事件(Event) ,则用户将会看到一个描述该对象总观的摘要(Summary)选项卡,选项卡的相关部分显示在两个视窗中,分别为属性(Properties)、关系(Related)、笔记和媒体(Notes & Media) 以及 历史(History) 。
本文将讨论文档选项卡和文档标记,然后讨论摘要选项卡以及两个视图中其他的项。
文档(Document)选项卡
Palantir中文档选项卡显示文档的原始文本。文档选项卡可以很好地从html、doc、docx、txt和pdf等多种文档格式中提取文本,并且也可以通过CEDT插件扩展来处理其他的文档格式,如msg。
文档选项卡的真正威力在于可以标记文档的内容,分析师用其构建非结构化数据,标记工具在文档上增加标识,以方便:
- 创建新的对象;
- 为已有对象创建新属性;
- 更新已有对象的已有属性;
- 建立对象之间的关联;
Palantir的文档搜索能力已经很强大了,有时候分析师会问为什么要标记,答案是,如果没有标记,则不能在Palantir对象模型中使用文档,那么也就大大地减少了执行分析的数据量。使用文档标记功能,所有被标记的对象都可以无缝地进行交互,并且在使用上与来自结构化数据源的数据相同。
做为示范,我们为Kevin Bacon和一篇关于Kevin Bacon的互联网文章做一个电影数据库条目。
下图中,一个人(Kevin Bacon)来自一个有线电影数据库TMDB,他拥有一些属性;其他的人如:Ruth Hilda Bacon、Edmund Norwood Bacon、Kyra Sedgwick、Travis Sedgwick Bacon和Sosie Ruth Bacon均为来自维基百科的一篇文章,所有这些人都是用那篇文章的内容关联起来的。
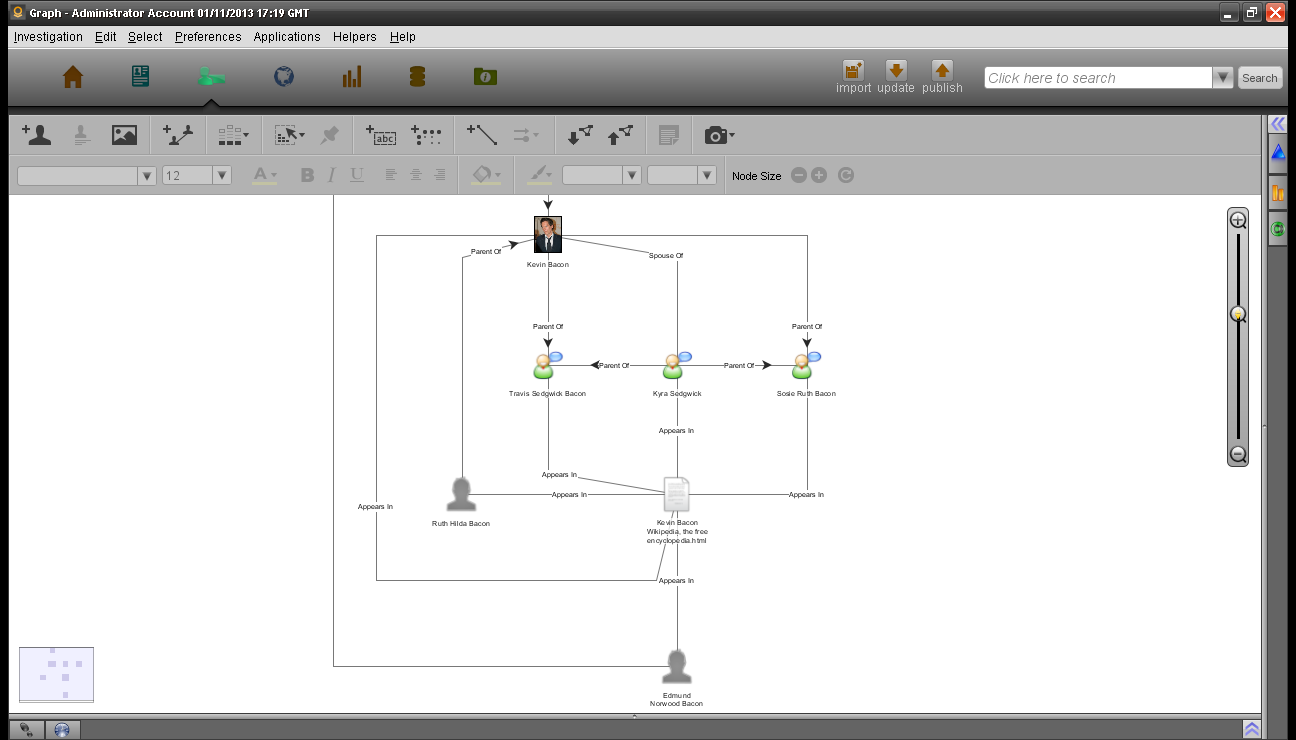
现在这个文档已经被标记了,分析师可以在分析图中用环形搜索(searcharound) 来搜索Kevin Bacon的关联实体,他的父母、妻子和孩子将会被搜索到,同样地搜索其中一个孩子的关联实体会返回其父母和其他兄弟姐妹,这些关联在对象探索(Object Explort) 中也可用来进行自顶向下的分析。当然,文档搜索也会找到该文档。
使用标记功能,系统中的所有添加项都可以溯源到原始文档,溯源对数据来源和完整性有保障,在依赖信息来做关键决策时这些(数据来源)是非常重要的。
实际上并没有一个最佳的标记方法!大多数部署应用应该有一套标准操作程序(SOP-Standard Operation Procedure),规定分析师应该遵循的标记操作,我更喜欢用近似的方式标记,但这只适用于与调查相关的数据,而且与被标记的那些事实存在合理的近似。
举例说明:如一份文件含有“英国是一个国家,英国有6000万居民”,那么我只会在第二次标记英国时才加上6000万居民作为英国的一个属性。下面是我标记Kevin Bacon文章的一个例子,实际上我给Kevin Bacon做了两次标记,一次关于他的童年,还有一次是关于他的家庭,而所有其他的人都只做一次标记。
如何标记?
在非结构化文档的视图中,有一个附加的选项卡——文档,选择这个选项卡显示文档的原始文本。通过以下过程实现“添加一个标记”:
- 选择要标记的文本,比如:电影名称,右键单击并选择“新建标记”;

- “新建标记”对话框出现,分析师可以选择系统中已有的实体来与文本关联或创建一个新的实体。用户可以修改标记的一些细节,比如:名称的值、或者添加地理信息和时间范围;
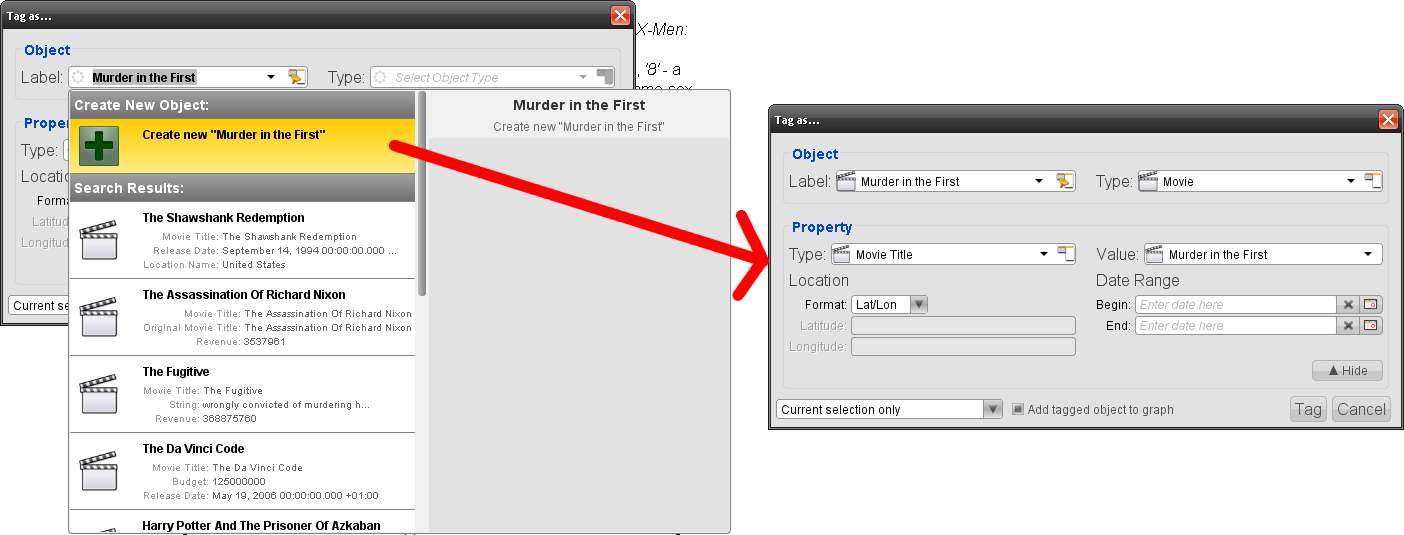
- 选择一些文本,然后拖放到已标记的实体中,以添加用户需要选择的新属性;
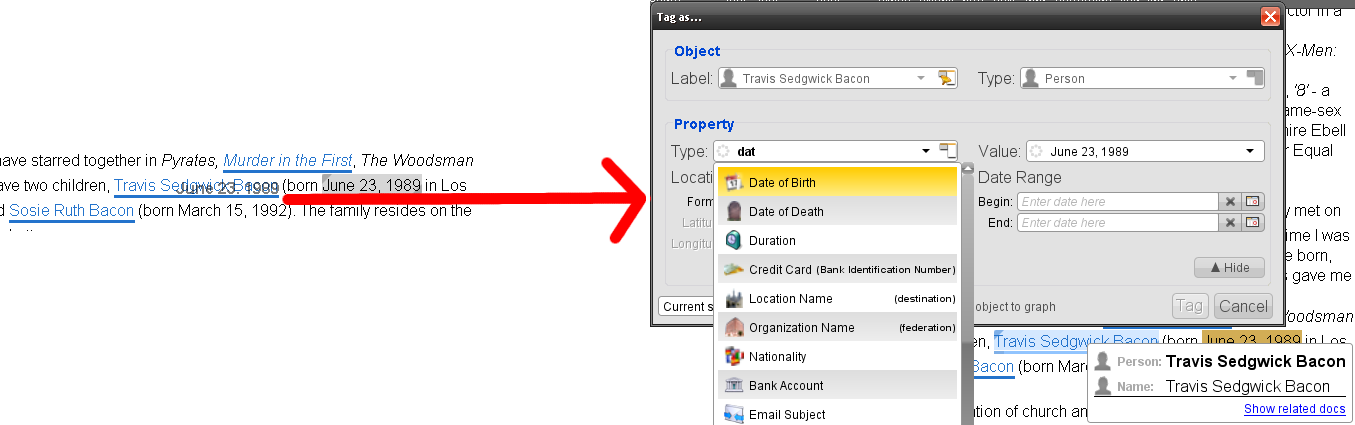
- 拖拽一个标记放置于另一个标记上,使用户能够在上下两层实体之间创建关系。
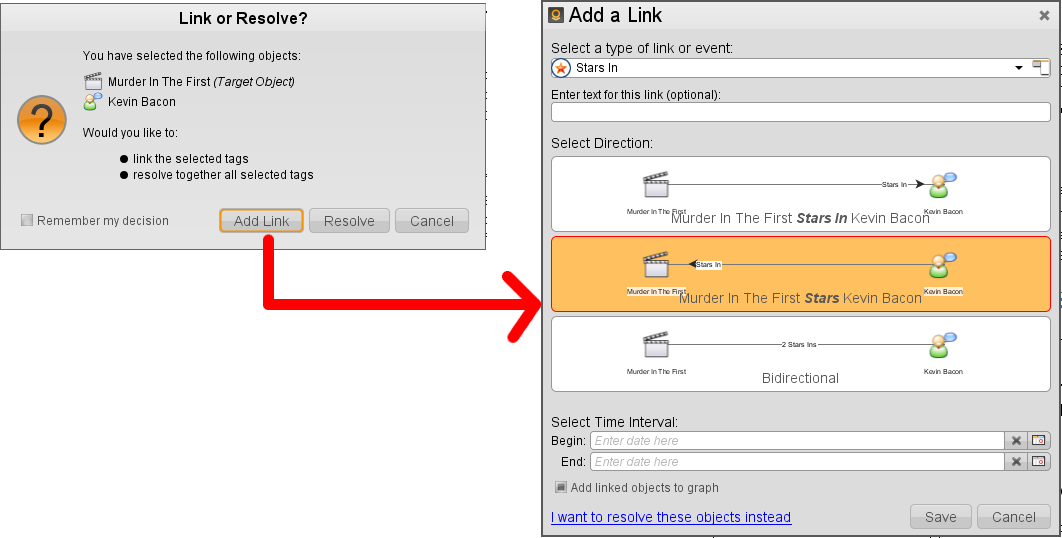
回到分析图中,此处再放一张根据标记而构建网状图——这是我利用标记而构建的图:
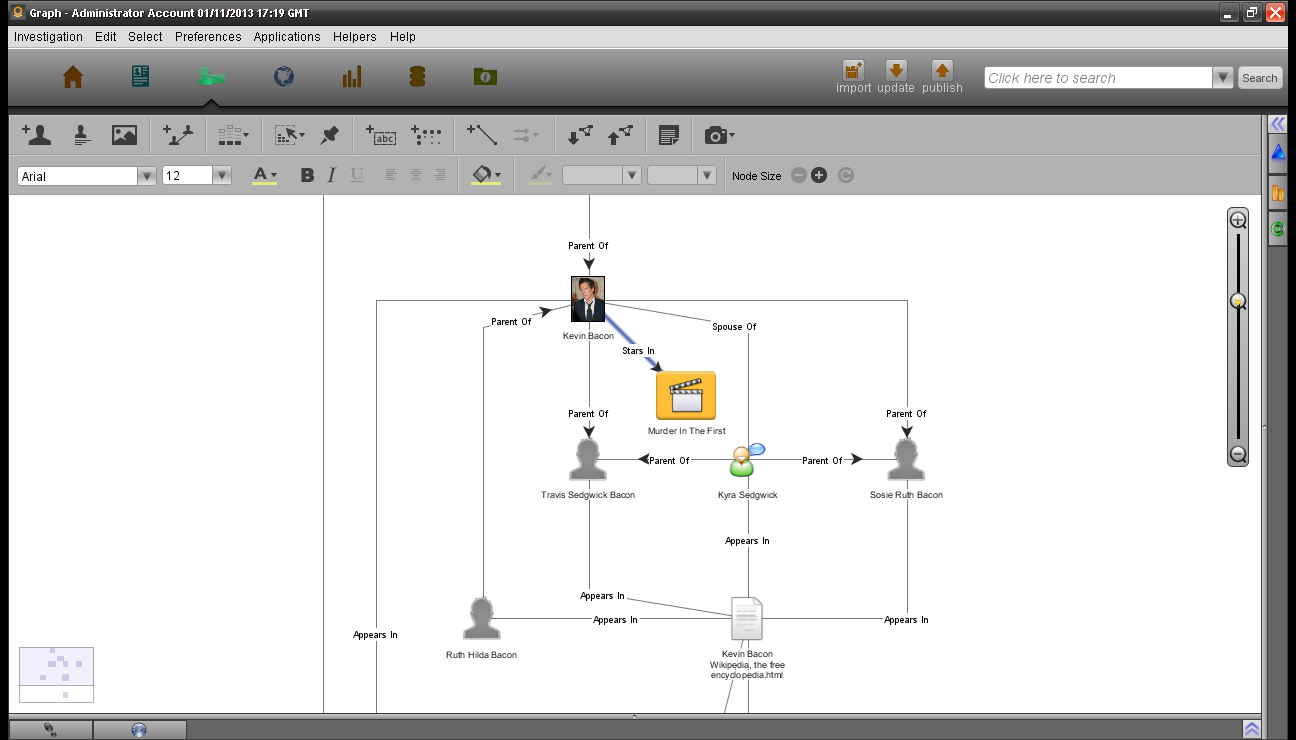
有3种工具可以轻松容易的进行标记,分别是:
-
查找和标记,该功能允许用户搜索文档的条目,然后标记一部分实体或所有实体。这种标记过程虽然快捷,但需要注意,单一主体的文档可能会被标记与实际情况不相符合,含糊的标注会导致问题。例如:如果标记道达尔(Total)石油公司的一篇新闻报道,文章可能会说“道达尔(Total)石油生产总值(Total)…”,在这种情况下道达尔(Total)和总值(Total)可能会被识别并错误地标记作为一个公司。与Palantir中的其他内容一样,任何错误都可以被纠正,但此处仍然需要注意。
-
实体提取服务器,该功能允许实体提取包(比如
NetOwl和SAP文本解析)的输出作为插件安装到Palantir中。实体提取工具非常强大,常常可以建立实体间的关联,也可以为每个实体建立属性。和Palantir一样,其通常依赖于本体,并将其显示在特定标记中所具有的特征。 -
V3.8版本还有一个实验性的标记推测服务,我目前还没有看到它的作用,帮助中说这个标记推测服务学习标记方法,可以对潜在的标记提出建议。
摘要(summary)选项卡
对于实体和事件,用户将看到一个摘要选项卡,选项卡是对正在查看对象的所有属性、关系、文档、笔记和历史的总观图。
下图例子是Kevin Bacon 的摘要选项卡,详细显示我们在此处看到的、涉及其他选项卡的内容。
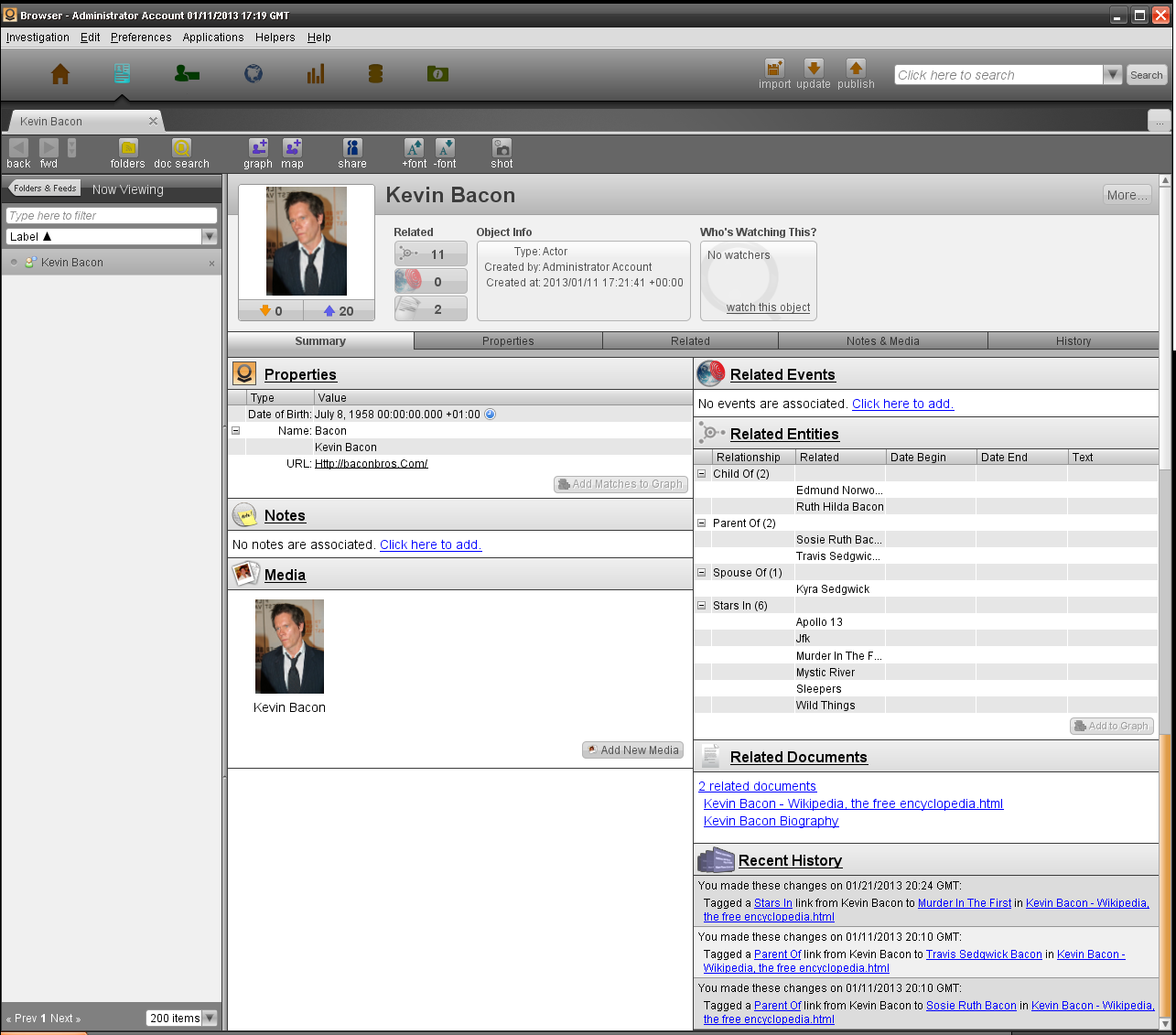
在摘要视图的顶部是一个免冠照片和一些对象元数据,内容包括谁创建对象、何时创建对象、以及对象类型;同时也有一部分显示谁在关注该对象,如果该对象有任何属性的改变,所有关注者将收到通知。
顶部最后一部分是免冠照片下面的两个箭头:橙色的向下箭头显示了可以用于该调查的Palantir基础库的更新数量,蓝色箭头显示存在该调查中可以发布到基础库的更新数量。
对于信息,所有的分析师都是私下分析,当需要分享他们的分析结果时,分析可以进行发布和分享,那么私人数据将被添加到基础库。当团队完成分析工作并发布后,私人调查中的数据可能会过时,因此,分析师应该更新他们的分析结果,从基础库里将最新的数据提取到私人调查结果中。
属性(Properties)选项卡
属性选项卡显示被查看的对象相关的所有属性;在选项卡的顶部用户可看到对象类型及对象的识别标签。
在属性部分,用户可以看到每个属性及其一个或多个属性值,如果使用分类控制访问(Classification Based Access Control- CBAC),则每个属性将会有一个分类访问条目。
那些不熟悉分类控制的人可能不知道,许多组织会根据业务的关键程度对数据进行分级,例如:当前的艾滋病列表可能被归类为机密,而人力资源记录可能被归类为秘密,因为前者应该更敏感。通过使用分类控制访问(CBAC),可以确保只有那些能够看到特定级别信息的人才能查看它。
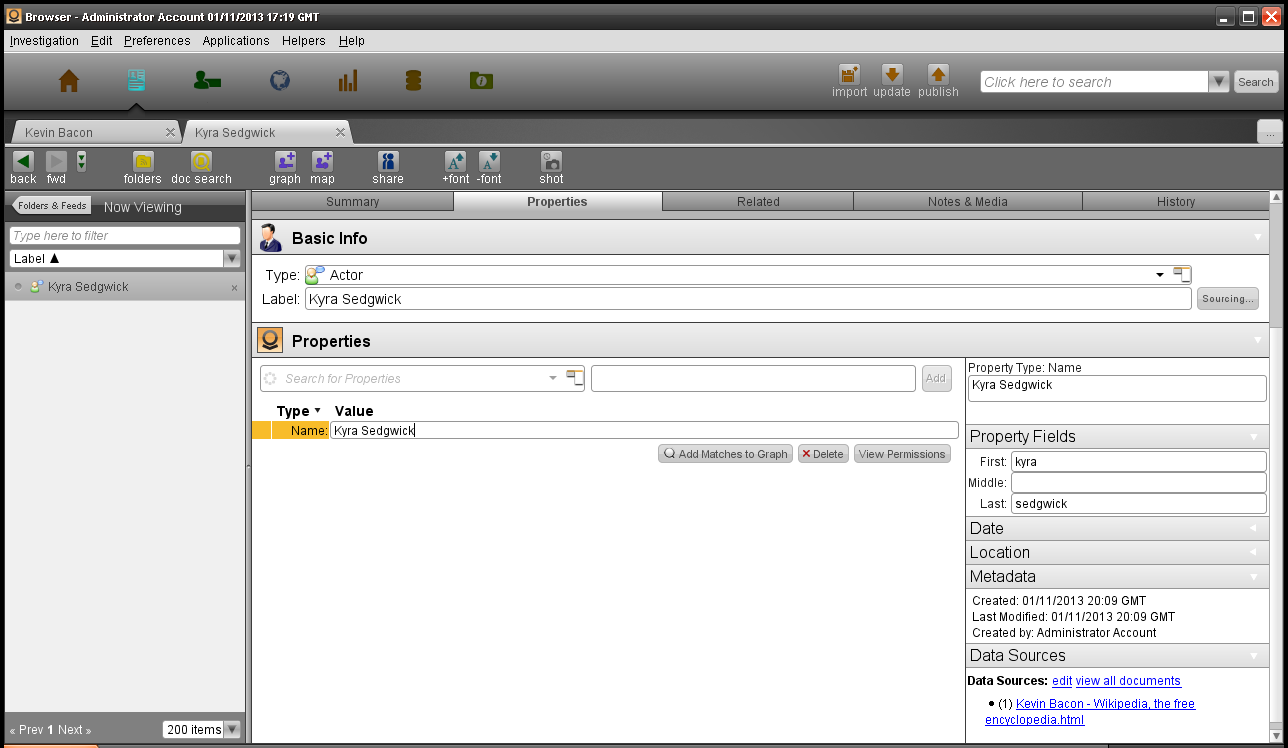
如果用户点击某个属性,屏幕右边则会显示该属性的元数据,包括:地理信息标记、日期范围和链接返回到信息源的信息。如果用户点击链接到源文件,则将被带到源文档中的位置——源文档内容被标记为属性的地方。所有导入系统的数据都可以溯源到它的源文件,增加对数据的信任并允许溯源错误。
关联(Related)选项卡
关联选项卡显示与被查看对象有关联的所有其他实体、事件和文档。
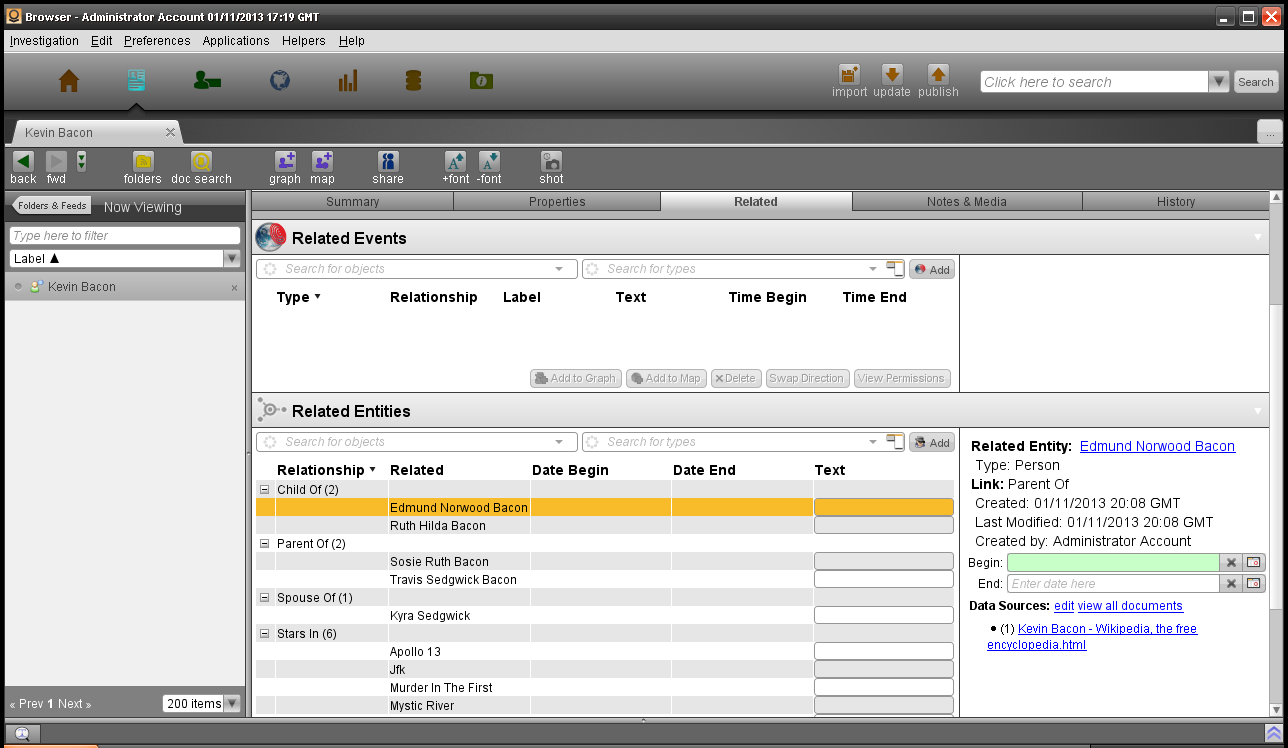
与属性选项卡一样,可以使用分类控制访问(CBAC)来控制对关联的访问,用户如果单击关联,就会看到元数据并关联返回到关联源。
笔记和媒体(Notes & Media)选项卡
用户可以自行创建笔记,并将其添加到系统的对象中,但是这些在分析过程中不会像文档那样形成积极的部分,因为笔记不能被标记,但是可以被搜索到,在非正式场景下非常有用。
同样,可以使用分类控制访问(CBAC)来控制笔记的访问,如果用户单击“笔记”,可以看到元数据和一个返回到笔记源的链接。媒体部分包含原始文档、视频、图像和声音文件,这些均为该对象的某种媒体源。
最后一次……媒体可以使用CBAC控制,如果用户单击媒体项目他们看到元数据和一个回到媒体来源的链接。
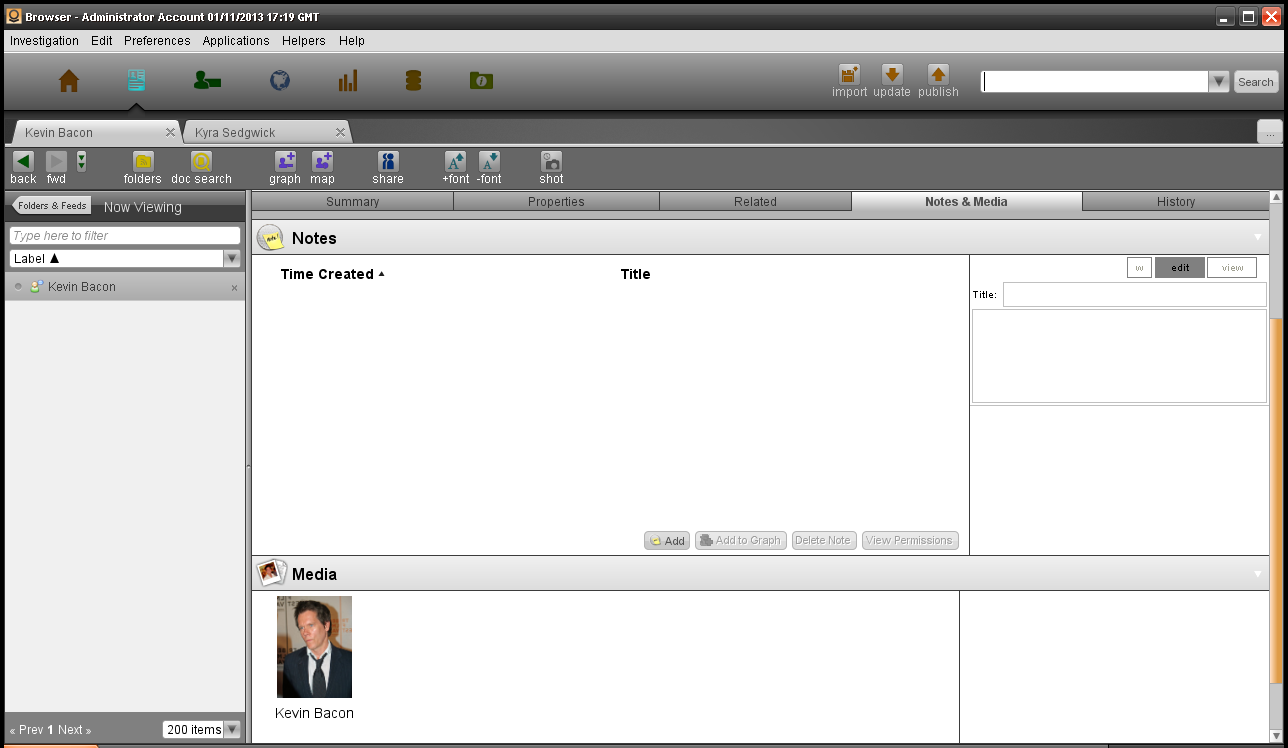
用户可以选择将任何图像作为该对象的免冠照片,就如前面看到的例子,Kevin Bacon有一个定制的免冠照片集,而Kyra Sedgwick使用了系统默认的免冠照片。
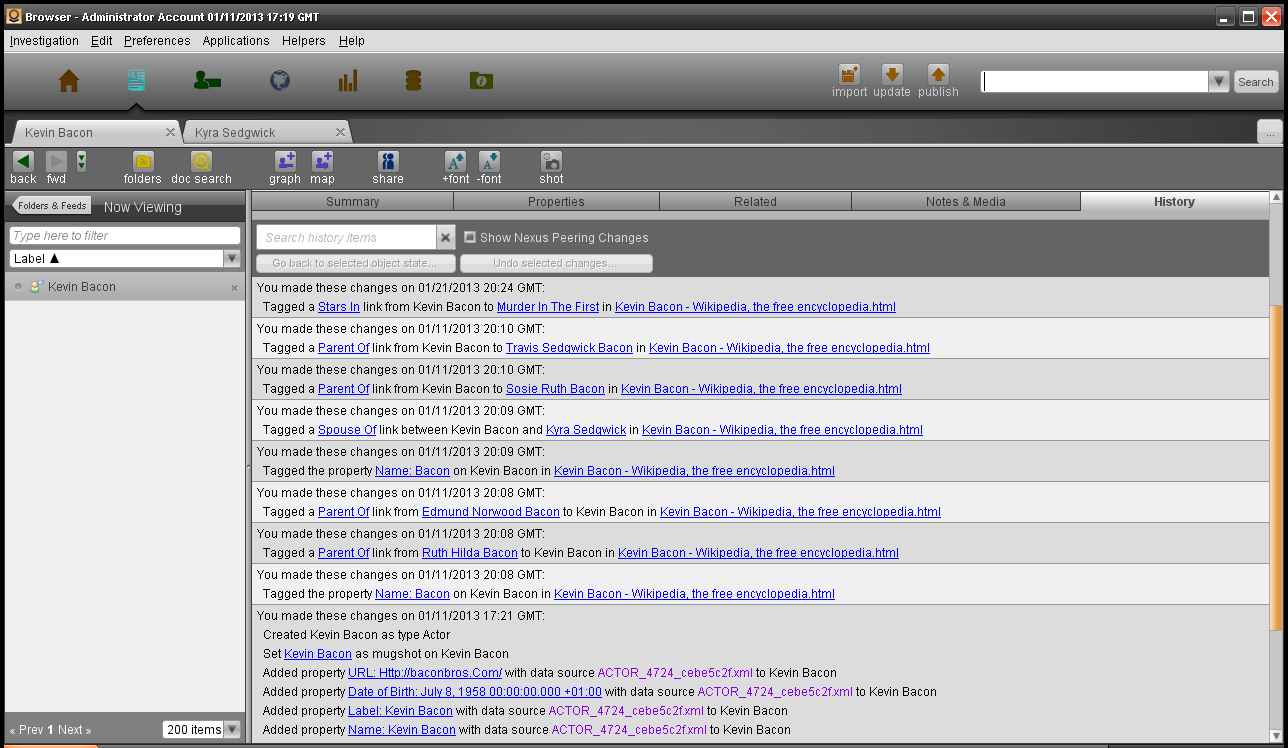
历史(History)选项卡
浏览器应用的最后一个选项卡是历史选项卡,可查看发生在该对象上包含日期/时间戳的审计日志。
使用历史选项卡,用户可以将对象恢复到以前的状态,或者从当前视图中删除以前的更新。对于数据管理非常有用,但也需要谨慎使用。
浏览器应用非常有用,在这里还有很多功能没有介绍,附加的功能如:文件夹和文档搜索可能成为后面文章的主题。现在,已经概述了组成应用的选项卡,并深入介绍了文档标记。
下一篇文章,将详细介绍图分析应用。
Palantir系列文章
- 硅谷最神秘的独角兽Palantir-01
- 什么是Palantir-02
- Palantir本体(Ontology)-03
- Palantir数据集成-04
- Palantir应用程序-05
- Palantir浏览器应用-06
- Palantir图分析应用-07
- Palantir SWOT分析-08
- Palantir分析:商业模式画布、SWOT、垄断特征、以及7个商业模式
